VietData.AI – Doanh nghiệp Việt đầu tiên tại Việt Nam đồng thời đạt danh hiệu Google Partner cho cả Google Cloud Platform & Google Marketing Platform, khẳng định năng lực tích hợp công nghệ và marketing vượt trội.
AI không chỉ học từ những con số 0 và 1! Đằng sau sức mạnh "hiểu" hình ảnh, giọng nói và ngôn ngữ là Tensor – định dạng dữ liệu đa chiều, Vector Embedding – ngôn ngữ số hóa của văn bản, và Distributed Storage – hạ tầng siêu khủng cho Cloud & Big Data. Muốn khai phá trọn vẹn tiềm năng của AI? Hãy bắt đầu bằng câu hỏi: "Dữ liệu máy tính lưu trữ dưới dạng gì?"
Tensor và Vector Embedding – “Ngôn Ngữ” Của AI để hiểu dữ liệu lưu trữ
Tensor: Định dạng lưu trữ dữ liệu đa chiều cho Deep Learning
Trong kỷ nguyên số, lượng dữ liệu khổng lồ được tạo ra mỗi ngày không chỉ đơn thuần là những con số 0 và 1, mọi thứ đều được số hóa và lưu trữ trong máy tính. Đặc biệt trong lĩnh vực Trí tuệ Nhân tạo (AI), dữ liệu trở nên phức tạp hơn bao giờ hết, từ hình ảnh, âm thanh đến ngôn ngữ tự nhiên. Vậy, dữ liệu máy tính lưu trữ dưới dạng gì để AI có thể "hiểu" và xử lý được sự đa dạng này?
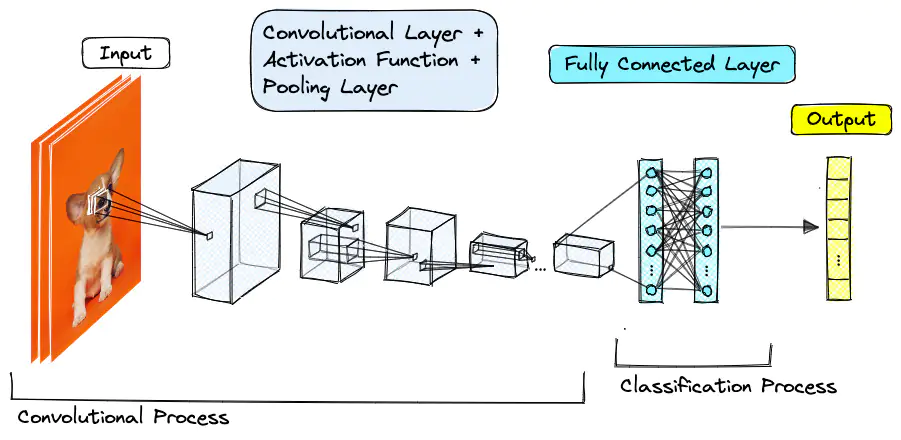
Để AI có thể "hiểu" và xử lý thông tin phức tạp, cần một định dạng mạnh mẽ hơn - Tensor chính là giải pháp. Tensor là một dạng ma trận mở rộng, có thể có 3 chiều, 4 chiều, hoặc thậm chí nhiều hơn, cho phép xử lý các loại dữ liệu phức tạp như ảnh màu - tensor 3 chiều với chiều cao, chiều rộng và kênh màu, âm thanh, hoặc chuỗi ngôn ngữ.
Trong Deep Learning, Tensor đóng vai trò là nguyên liệu đầu vào cho các mô hình như Convolutional Neural Networks (CNN) trong xử lý ảnh và Transformer models (như GPT) trong xử lý ngôn ngữ tự nhiên. Không chỉ giúp máy tính quản lý thông tin hiệu quả hơn mà còn tối ưu hóa các phép toán phức tạp cần thiết cho quá trình học của AI.
Vector Embedding: Biến văn bản thành số để AI "hiểu" ngữ nghĩa.
Một thách thức lớn trong việc làm cho AI "hiểu" là ngôn ngữ của con người. Văn bản không có cấu trúc rõ ràng như dữ liệu số. Đây là nơi Vector Embedding phát huy tác dụng. Vector Embedding là một kỹ thuật chuyển đổi văn bản (từ, câu, đoạn văn) thành các vector số trong một không gian nhiều chiều.
Đặc biệt, các vector này được thiết kế sao cho các từ hoặc cụm từ có ý nghĩa tương tự sẽ nằm gần nhau trong không gian vector. Nhờ đó, AI có thể "hiểu" được ngữ cảnh và ý nghĩa của văn bản thay vì chỉ nhận diện các từ khóa đơn thuần.
DeepSeek từ cái tên xa lạ bỗng trở thành “vua chúa” trong giới AI
Khi các mô hình ngôn ngữ như Word2Vec, BERT và GPT từng bước cách mạng hóa cách AI hiểu ngôn ngữ tự nhiên, thì DeepSeek xuất hiện với một bước nhảy vọt, không chỉ theo kịp mà còn định nghĩa lại cuộc chơi. Trọng tâm thành công nằm ở cách DeepSeek ứng dụng kỹ thuật nhúng nâng cao. Nhờ tích hợp kiến trúc Multi-head Latent Attention (MLA) và Mixture-of-Experts (MoE), DeepSeek cải thiện đáng kể cả hiệu quả lẫn độ chính xác trong việc biểu diễn dữ liệu dưới dạng vector – một yếu tố cốt lõi giúp AI “hiểu” ý nghĩa chứ không chỉ từ ngữ.
Các ứng dụng như tìm kiếm ngữ nghĩa chính xác hơn, chatbot giữ ngữ cảnh mượt mà hơn, hay nhận diện hình ảnh có chiều sâu hơn đều được cải thiện vượt trội. Trong thời đại mà Vector Embedding trở thành nền tảng cho truy xuất thông minh và hiểu ngôn ngữ nâng cao, DeepSeek không còn là kẻ đứng ngoài mà là người dẫn đầu, nhờ chọn đúng hướng đi tại đúng thời điểm.
Tìm hiểu thêm về cách DeepSeek cách mạng hóa "sân chơi AI":
Song song với sự bứt phá đó, một làn sóng khác cũng âm thầm lan rộng: AI đang trở nên dễ tiếp cận hơn, rẻ hơn – nhưng không kém phần mạnh mẽ. Trước đây, triển khai AI đồng nghĩa với chi phí cao và yêu cầu hạ tầng phức tạp, khiến nhiều doanh nghiệp nhỏ khó tiếp cận. Tuy nhiên, sự xuất hiện của các mô hình nhẹ, tối ưu tài nguyên, cùng với nền tảng cloud phi tập trung, đã thay đổi hoàn toàn cuộc chơi. Giờ đây, AI giá rẻ không còn là lựa chọn thỏa hiệp, mà là một hướng đi chiến lược, nơi hiệu suất được tối ưu mà vẫn phù hợp ngân sách. Chính sự kết hợp giữa kỹ thuật hiện đại và hạ tầng linh hoạt đang đưa AI đến gần hơn với đời sống và kinh doanh thực tiễn – mở ra không gian sáng tạo mới với chi phí hợp lý.
Distributed Storage – Xương Sống của Cloud và Big Data trong lưu trữ dữ liệu
Tại sao cần Distributed Storage cho Cloud và Big Data?
Sự bùng nổ của AI và Big Data đã tạo ra một lượng dữ liệu khổng lồ, các hệ thống lưu trữ truyền thống không còn đáp ứng được yêu cầu này. Distributed Storage đã nổi lên như một giải pháp tối ưu, cho phép phân tán dữ liệu trên nhiều máy chủ, mang lại khả năng mở rộng, hiệu suất và độ tin cậy cần thiết cho các ứng dụng AI.
Các nền tảng đám mây như AWS S3 và Google Cloud Storage cung cấp các dịch vụ phân tán mạnh mẽ, giúp các nhà nghiên cứu và doanh nghiệp dễ dàng quản lý và truy cập lượng lớn dữ liệu để huấn luyện các mô hình AI phức tạp và phân tích Big Data.
Điều này mang lại nhiều lợi ích quan trọng:
Khả năng mở rộng vô hạn (Scalability): Hệ thống có thể dễ dàng mở rộng dung lượng khi cần thiết mà không gặp giới hạn cứng.
Xử lý song song (Parallel Computing): Dữ liệu được phân tán cho phép xử lý đồng thời trên nhiều node, tăng tốc đáng kể hiệu suất phân tích và huấn luyện mô hình AI.
Độ tin cậy cao: Dữ liệu được sao chép và phân tán, đảm bảo an toàn và khả năng phục hồi ngay cả khi một phần hệ thống gặp sự cố.
Các định dạng lưu trữ dữ liệu phân tán trên Cloud cho AI và Big Data.
Các nền tảng Cloud cung cấp nhiều định dạng lưu trữ dữ liệu phân tán để phù hợp với các loại dữ liệu và nhu cầu khác nhau của AI và Big Data:
Lưu Trữ Dữ Liệu Có Cấu Trúc (SQL): Thường được triển khai trên hạ tầng phân tán để xử lý dữ liệu có cấu trúc rõ ràng.
Lưu Trữ Dữ Liệu Phi Cấu Trúc (NoSQL): Các hệ thống NoSQL như MongoDB, Cassandra được thiết kế để xử lý lượng lớn dữ liệu phi cấu trúc (văn bản, hình ảnh, video) thường gặp trong các ứng dụng AI và Big Data.
Lưu Trữ Dữ Liệu Thời Gian Thực (Datastream): Các nền tảng như Kafka, Spark Streaming cho phép lưu trữ và xử lý các luồng dữ liệu liên tục theo thời gian thực, quan trọng cho các ứng dụng IoT và phân tích sự kiện.
Lưu Trữ Mô Hình AI (TensorFlow Save Model): Các nền tảng Cloud cung cấp các giải pháp tối ưu hóa và triển khai các mô hình AI đã được huấn luyện, giúp dễ dàng đưa AI vào ứng dụng thực tế.
Ứng Dụng Thực Tế của Distributed Storage trong Lưu Trữ Dữ Liệu AI và Big Data.
Netflix: Sử dụng cơ sở dữ liệu phân tán (ví dụ: Cassandra) để lưu trữ dữ liệu về lịch sử xem phim, sở thích của người dùng và thông tin về nội dung, từ đó xây dựng các hệ thống đề xuất nội dung cá nhân hóa và cải thiện trải nghiệm người dùng.
Tesla: Ứng dụng các hệ thống streaming (ví dụ: Apache Kafka) để thu thập và xử lý cảm biến từ hàng triệu xe tự lái trong thời gian thực. Lượng dữ liệu khổng lồ này được sử dụng để huấn luyện các mô hình AI phức tạp, giúp xe tự lái an toàn hơn và cải thiện hiệu suất.
Các nền tảng thương mại điện tử: Sử dụng Distributed Storage để quản lý lượng lớn dữ liệu về sản phẩm, khách hàng, lịch sử giao dịch và hành vi duyệt web, từ đó phân tích xu hướng mua sắm, cá nhân hóa trải nghiệm mua sắm và dự đoán nhu cầu của khách hàng
Sự thay đổi trong cách dữ liệu được lưu trữ mở ra tiềm năng cho AI
Từ nền tảng binary đơn giản đến các cấu trúc phức tạp như Tensor và Vector Embedding, cùng với hạ tầng phân tán mạnh mẽ của Cloud và Big Data, chúng ta đang chứng kiến sự tiến bộ vượt bậc của trí tuệ nhân tạo. Việc hiểu rõ dữ liệu máy tính lưu trữ dưới dạng gì và cách nó được quản lý là chìa khóa để khai thác tối đa sức mạnh của AI và xây dựng một tương lai thông minh hơn.
Doanh nghiệp đang ưu tiên AI trong tuyển dụng Nhiều doanh nghiệp đã triển khai AI để xử lý và đánh giá hồ sơ ứng viên nhanh hơn. Theo Zoho Recruit, các phần mềm như hệ thống ATS có thể sàng lọc hàng trăm hồ sơ chỉ trong vài phút, dựa vào các từ khóa […]
Cảm ơn bạn đã tin tưởng và lựa chọn chúng tôi. Đội ngũ của chúng tôi sẽ sớm liên hệ lại để hỗ trợ bạn nhanh chóng nhất
Chúng tôi tôn trọng quyền riêng tư của bạn
Chúng tôi sử dụng cookie để nâng cao trải nghiệm duyệt web của bạn, cung cấp quảng cáo hoặc nội dung cá nhân hóa và phân tích lưu lượng truy cập của chúng tôi. Bằng cách nhấp vào 'Chấp nhận tất cả,' bạn đồng ý với việc chúng tôi sử dụng cookie. Chính sách Cookie.
CHÍNH SÁCH QUYỀN RIÊNG TƯ DÀNH CHO CHỦ THỂ DỮ LIỆU LÀ KHÁCH HÀNG
1. Quy định chung
1.1. Chính Sách Quyền Riêng Tư Dành Cho Chủ Thể Dữ Liệu Là Khách Hàng (“Chính Sách”) này mô tả việc Chúng Tôi Xử Lý Dữ Liệu Cá Nhân của Chủ Thể Dữ Liệu khi Chủ Thể Dữ Liệu tương tác và/hoặc thực hiện thoả thuận với Chúng Tôi.
1.2. Dẫn chiếu đến Chúng Tôi theo Chính Sách này sẽ bao gồm:
1.2.1. Chúng Tôi, tức Công ty TNHH VIETDATA AI, mã số doanh nghiệp 6101172020;
1.2.2. Chi nhánh, văn phòng đại diện, công ty mẹ, công ty con, công ty liên kết của Chúng Tôi;
1.2.3. Tổ chức, cá nhân cung cấp sản phẩm, dịch vụ cho Chúng Tôi;
1.2.4. Tổ chức, cá nhân hợp tác với Chúng Tôi;
1.2.5. Nhân sự, bên đại diện, bên được uỷ quyền của Chúng Tôi và bất kỳ tổ chức, cá nhân nào nêu trên.
1.3. Đôi khi Chúng Tôi sẽ cập nhật Chính Sách này để phản ánh những thay đổi trong hoạt động của Chúng Tôi. Khi Chúng Tôi đăng các thay đổi đối với Chính Sách này, Chúng Tôi sẽ sửa lại Ngày Cập Nhật Lần Cuối ở phần đầu. Nếu Chúng Tôi thực hiện bất kỳ thay đổi quan trọng nào trong loại Dữ Liệu Cá Nhân được Xử Lý, mục đích Xử Lý Dữ Liệu Cá Nhân, tổ chức, cá nhân được Xử Lý Dữ Liệu Cá Nhân, quyền và nghĩa vụ của Chủ Thể Dữ Liệu, Chúng Tôi sẽ thông báo cho Chủ Thể Dữ Liệu bằng cách đăng thông báo rõ ràng về những thay đổi đó trên Website và/hoặc gửi đến thông tin liên hệ mà Chủ Thể Dữ Liệu đã cung cấp cho Chúng Tôi để Chủ Thể Dữ Liệu thực hiện quyền của mình nếu cần thiết theo quy định Pháp Luật. Chúng Tôi khuyến nghị Chủ Thể Dữ Liệu thường xuyên kiểm tra để cập nhật các thay đổi đối với Chính Sách này.
1.4. Chủ Thể Dữ Liệu xác nhận rằng bằng việc tương tác với Chúng Tôi và/hoặc cung cấp Dữ Liệu Cá Nhân cho Chúng Tôi dưới mọi hình thức, Chủ Thể Dữ Liệu đã đồng ý toàn bộ và không kèm theo bất kỳ điều kiện nào đối với Chính Sách này và các cập nhật (nếu có) tuỳ từng thời điểm. Nếu không đồng ý một phần hoặc toàn bộ Chính Sách này, Chủ Thể Dữ Liệu vui lòng không tương tác và/hoặc không cung cấp Dữ Liệu Cá Nhân cho Chúng Tôi dưới mọi hình thức.
1.5. Bằng việc đồng ý với Chính Sách này theo Điều 1.4, Chủ Thể Dữ Liệu xác nhận đã:
1.5.1. Đồng ý để Dữ Liệu Cá Nhân được Xử Lý bởi Chúng Tôi, tổ chức, cá nhân được Xử Lý Dữ Liệu Cá Nhân như nêu tại Chính Sách này;
1.5.2. Biết rõ loại Dữ Liệu Cá Nhân được Xử Lý, mục đích Xử Lý Dữ Liệu Cá Nhân, tổ chức, cá nhân được Xử Lý Dữ Liệu Cá Nhân, quyền và nghĩa vụ của mình liên quan đến Dữ Liệu Cá Nhân;
1.5.3. Được Chúng Tôi thông báo, hiểu và đồng ý với toàn bộ các nội dung cần được thông báo trước khi Dữ Liệu Cá Nhân được Xử Lý bởi Chúng Tôi, tổ chức, cá nhân được Xử Lý Dữ Liệu Cá Nhân; và
1.5.4. Đồng ý rằng Chúng Tôi, tổ chức, cá nhân được Xử Lý Dữ Liệu Cá Nhân không cần thực hiện thông báo lại trước khi Xử Lý Dữ Liệu Cá Nhân.
1.6. Trong Chính Sách này, một số từ và cụm từ có nghĩa như sau:
1.6.1. “Chủ Thể Dữ Liệu” nghĩa là cá nhân được Dữ Liệu Cá Nhân phản ánh.
1.6.2. “Dữ Liệu Cá Nhân” nghĩa là thông tin dưới dạng ký hiệu, chữ viết, chữ số, hình ảnh, âm thanh hoặc dạng tương tự trên môi trường điện tử gắn liền với một con người cụ thể hoặc giúp xác định một con người cụ thể. Dữ Liệu Cá Nhân bao gồm Dữ Liệu Cá Nhân cơ bản và Dữ Liệu Cá Nhân nhạy cảm theo quy định Pháp Luật.
1.6.3. “ Pháp Luật” nghĩa là toàn bộ các điều khoản và quy định của pháp luật nước Cộng hoà Xã hội Chủ nghĩa Việt Nam hiện hành có liên quan đến Chính Sách này.
1.6.4. “Xử Lý Dữ Liệu Cá Nhân” hoặc “Xử Lý” nghĩa là một hoặc nhiều hoạt động tác động tới Dữ Liệu Cá Nhân, như: thu thập, ghi, phân tích, xác nhận, lưu trữ, chỉnh sửa, công khai, kết hợp, truy cập, truy xuất, thu hồi, mã hóa, giải mã, sao chép, chia sẻ, truyền đưa, cung cấp, chuyển giao, xóa, hủy dữ liệu cá nhân hoặc các hành động khác có liên quan.
1.7. Mọi dẫn chiếu đến một quy định hoặc tài liệu sẽ bao gồm dẫn chiếu đến các sửa đổi hoặc thay thế tương ứng của quy định hoặc tài liệu đó.
1.8. Các đầu mục và tiêu đề trong Chính Sách này chỉ cho mục đích thuận tiện theo dõi mà không ảnh hưởng đến nội dung của các điều khoản đó.
1.9. Các từ, cụm từ không được định nghĩa tại Chính Sách này sẽ có nghĩa như quy định tại Điều Khoản Và Điều Kiện Sử Dụng Website. Nếu Điều Khoản Và Điều Kiện Sử Dụng Website không định nghĩa thì thực hiện theo quy định Pháp Luật.
1.10. Khi Chủ Thể Dữ Liệu cung cấp Dữ Liệu Cá Nhân cho Chúng Tôi, Chủ Thể Dữ Liệu đồng ý, cam đoan, bảo đảm và chịu trách nhiệm rằng:
1.10.1. Dữ Liệu Cá Nhân là đầy đủ, chính xác, trung thực, hợp pháp. Chủ Thể Dữ Liệu sẽ thông báo cho Chúng Tôi về bất kỳ thay đổi nào đối với Dữ Liệu Cá Nhân do Chủ Thể Dữ Liệu cung cấp. Chúng Tôi không có nghĩa vụ và trách nhiệm thẩm định, xác minh tính đầy đủ, chính xác, trung thực, hợp pháp của Dữ Liệu Cá Nhân, cũng như được miễn trừ mọi trách nhiệm liên quan khi Chủ Thể Dữ Liệu không thông báo cho Chúng Tôi về bất kỳ thay đổi nào đối với Dữ Liệu Cá Nhân do Chủ Thể Dữ Liệu cung cấp.
1.10.2. Chủ Thể Dữ Liệu sẽ không cung cấp cho Chúng Tôi Dữ Liệu Cá Nhân của người chưa đủ mười tám (18) tuổi và/hoặc người không có năng lực hành vi dân sự đầy đủ.
1.10.3. Chủ Thể Dữ Liệu sẽ bảo vệ và giữ cho Chúng Tôi không bị thiệt hại, đồng thời Chủ Thể Dữ Liệu đồng ý bồi thường cho Chúng Tôi toàn bộ thiệt hại (bao gồm cả chi phí luật sư) mà Chúng Tôi phải gánh chịu do bất kỳ khiếu nại, khiếu kiện, tranh chấp nào phát sinh từ hoặc liên quan đến việc Chủ Thể Dữ Liệu không thực hiện đúng nội dung quy định này.
1.11. Việc Nền Tảng Của Bên Thứ Ba xử lý Dữ Liệu Cá Nhân của Chủ Thể Dữ Liệu được thực hiện theo quy định của Nền Tảng Của Bên Thứ Ba tương ứng, nằm ngoài tầm kiểm soát của Chúng Tôi. Chủ Thể Dữ Liệu xác nhận và đồng ý rằng Chúng Tôi không chịu mọi trách nhiệm liên quan đến việc xử lý này.
2. Loại dữ liệu cá nhân được xử lý
2.1. Chúng Tôi có thể Xử Lý Dữ Liệu Cá Nhân cơ bản sau đây:
2.1.1. Họ, chữ đệm và tên khai sinh, tên gọi khác (nếu có);
2.1.2. Giới tính;
2.1.3. Địa chỉ liên hệ;
2.1.4. Quốc tịch;
2.1.5. Số điện thoại;
2.1.6. Hình ảnh của cá nhân;
2.1.7. Thông tin tài khoản số của cá nhân;
2.1.8. Các thông tin khác gắn liền với một con người cụ thể hoặc giúp xác định một con người cụ thể không thuộc quy định tại Điều 2.2 bên dưới.
2.2. Chúng Tôi có thể Xử Lý Dữ Liệu Cá Nhân nhạy cảm sau đây:
2.2.1. Thông tin khách hàng của tổ chức tín dụng, chi nhánh ngân hàng nước ngoài, tổ chức cung ứng dịch vụ trung gian thanh toán, các tổ chức được phép khác, gồm: thông tin định danh khách hàng theo quy định của pháp luật, thông tin về tài khoản, thông tin về giao dịch;
2.2.2. Dữ liệu cá nhân khác được Pháp Luật quy định là đặc thù và cần có biện pháp bảo mật cần thiết.
3. Mục đích xử lý dữ liệu cá nhân
Chúng Tôi Xử Lý Dữ Liệu Cá Nhân theo Điều 2 vì một hoặc nhiều mục đích sau:
3.1. Liên hệ và xử lý yêu cầu của Chủ Thể Dữ Liệu.
3.2. Xác lập và/hoặc duy trì quan hệ với Chủ Thể Dữ Liệu.
3.3. Tuân thủ Pháp Luật.
3.4. Các mục đích khác mà Chủ Thể Dữ Liệu đồng ý.
3.5. Xây dựng và/hoặc phát triển hoạt động kinh doanh, sản phẩm, dịch vụ, Website và/hoặc Nội Dung Website của Chúng Tôi.
3.6. Quảng cáo, tiếp thị cho Chủ Thể Dữ Liệu.
4. Cách thức xử lý dữ liệu cá nhân
4.1. Thu thập:
4.1.1. Đối với Dữ Liệu Cá Nhân cơ bản:
4.1.1.1. Do Chủ Thể Dữ Liệu tự nguyện cung cấp cho Chúng Tôi;
4.1.1.2. Do Nền Tảng Của Bên Thứ Ba hiển thị khi Chúng Tôi liên hệ với Chủ Thể Dữ Liệu thông qua Nền Tảng Của Bên Thứ Ba;
4.1.1.3. Do cơ quan, tổ chức, cá nhân có thẩm quyền cung cấp một cách hợp pháp.
4.1.2. Đối với Dữ Liệu Cá Nhân nhạy cảm:
4.1.2.1. Do Chủ Thể Dữ Liệu tự nguyện cung cấp cho Chúng Tôi;
4.1.2.2. Do cơ quan, tổ chức, cá nhân có thẩm quyền cung cấp một cách hợp pháp.
4.2. Phân tích: Dữ Liệu Cá Nhân được phân tích dựa trên quy trình nội bộ của Chúng Tôi, nguyên tắc bảo vệ, bảo mật dữ liệu đối với hệ thống công nghệ thông tin.
4.3. Lưu trữ:
4.3.1. Dữ Liệu Cá Nhân được lưu trữ trong cơ sở dữ liệu Chúng Tôi.
4.3.2. Thời gian lưu trữ Dữ Liệu Cá Nhân được xác định căn cứ vào mục đích Xử Lý quy định tại Chính Sách này và phù hợp với quy định Pháp Luật.
4.4. Mã hoá: Khi cần thiết, Dữ Liệu Cá Nhân thu thập được mã hóa theo các tiêu chuẩn mã hóa phù hợp trong quá trình Xử Lý để đảm bảo các dữ liệu luôn được bảo vệ.
4.5. Chia sẻ/truyền đưa/cung cấp:
4.5.1. Dữ Liệu Cá Nhân được chia sẻ/truyền đưa/cung cấp cho các tổ chức, cá nhân khác có liên quan tới mục đích Xử Lý Dữ Liệu Cá Nhân theo Chính Sách này.
4.5.2. Chúng Tôi sử dụng các biện pháp bảo vệ, bảo mật cần thiết để đảm bảo việc chia sẻ/truyền đưa/cung cấp Dữ Liệu Cá Nhân được an toàn.
4.6. Chuyển ra nước ngoài: Chúng Tôi sẽ thực hiện theo quy định Pháp Luật về việc chuyển Dữ Liệu Cá Nhân ra nước ngoài.
4.7. Xoá:
Theo quy định Pháp Luật hoặc theo yêu cầu hợp lệ từ Chủ Thể Dữ Liệu, Chúng Tôi sẽ xóa Dữ Liệu Cá Nhân mà Chúng Tôi đang Xử Lý, trừ trường hợp sau đây:
4.7.1. Pháp Luật quy định không cho phép xóa hoặc yêu cầu bắt buộc phải lưu trữ Dữ Liệu Cá Nhân;
4.7.2. Dữ Liệu Cá Nhân được xử lý bởi cơ quan nhà nước có thẩm quyền với mục đích phục vụ hoạt động của cơ quan nhà nước theo quy định Pháp Luật;
4.7.3. Dữ Liệu Cá Nhân đã được công khai theo quy định Pháp Luật;
4.7.4. Dữ Liệu Cá Nhân được xử lý nhằm phục vụ yêu cầu pháp lý, nghiên cứu khoa học, thống kê theo quy định Pháp Luật;
4.7.5. Trong trường hợp tình trạng khẩn cấp về quốc phòng, an ninh quốc gia, trật tự an toàn xã hội, thảm họa lớn, dịch bệnh nguy hiểm; khi có nguy cơ đe dọa an ninh, quốc phòng nhưng chưa đến mức ban bố tình trạng khẩn cấp; phòng, chống bạo loạn, khủng bố, phòng, chống tội phạm và vi phạm Pháp Luật; hoặc
4.7.6. Ứng phó với tình huống khẩn cấp đe dọa đến tính mạng, sức khỏe hoặc sự an toàn của Chủ Thể Dữ Liệu hoặc cá nhân khác.
5. Các tổ chức, cá nhân khác có liên quan tới mục địch xử lý
Trong phạm vi Pháp Luật cho phép, các tổ chức, cá nhân sau có liên quan tới mục đích Xử Lý theo Chính Sách này:
5.1. Chi nhánh, văn phòng đại diện, công ty mẹ, công ty con, công ty liên kết của Chúng Tôi;
5.2. Tổ chức, cá nhân cung cấp sản phẩm, dịch vụ cho Chúng Tôi;
5.3. Tổ chức, cá nhân hợp tác với Chúng Tôi;
5.4. Nhân sự, bên đại diện, bên được uỷ quyền của Chúng Tôi và bất kỳ tổ chức nào nêu trên;
5.5. Bất kỳ cá nhân, tổ chức nào là bên đại diện, bên được ủy quyền của Chủ Thể Dữ Liệu, hành động thay mặt Chủ Thể Dữ Liệu;
5.6. Cơ quan nhà nước có thẩm quyền theo quy định Pháp Luật.
6. Hậu quả, thiệt hại không mong muốn có khả năng xảy ra
6.1. Chúng Tôi sử dụng nhiều công nghệ bảo vệ, bảo mật khác nhau như hệ thống tường lửa, các biện pháp kiểm soát truy cập, mã hóa… nhằm bảo vệ và ngăn chặn việc Dữ Liệu Cá Nhân bị truy cập, sử dụng hoặc chia sẻ trái phép. Tuy nhiên, Chúng Tôi không thể cam kết bảo đảm an toàn một cách tuyệt đối Dữ Liệu Cá Nhân trong một số trường hợp như:
6.1.1. Lỗi phần cứng, phần mềm trong quá trình Xử Lý làm mất Dữ Liệu Cá Nhân của Chủ Thể Dữ Liệu;
6.1.2. Lỗ hổng bảo mật nằm ngoài khả năng kiểm soát của Chúng Tôi, hệ thống bị hacker tấn công gây lộ, lọt Dữ Liệu Cá Nhân.
6.2. Chủ Thể Dữ Liệu cần biết rõ rằng bất kỳ thời điểm nào khi Chủ Thể Dữ Liệu tiết lộ và công khai Dữ Liệu Cá Nhân của mình, dữ liệu đó có thể bị người khác thu thập và sử dụng cho các mục đích nằm ngoài tầm kiểm soát của Chủ Thể Dữ Liệu và Chúng Tôi.
6.3. Trong trường hợp máy chủ lưu trữ dữ liệu bị tấn công dẫn đến bị mất, lộ, lọt Dữ Liệu Cá Nhân, Chúng Tôi có trách nhiệm thông báo vụ việc cho cơ quan chức năng điều tra xử lý kịp thời và thông báo cho Chủ Thể Dữ Liệu được biết theo quy định Pháp Luật.
6.4. Không gian mạng không phải là một môi trường tuyệt đối an toàn và Chúng Tôi không thể đảm bảo tuyệt đối rằng Dữ Liệu Cá Nhân được chia sẻ qua không gian mạng sẽ luôn được bảo vệ, bảo mật. Khi truyền tải Dữ Liệu Cá Nhân qua không gian mạng, Chủ Thể Dữ Liệu chỉ nên sử dụng các hệ thống an toàn để truy cập Website và/hoặc Nền Tảng Của Bên Thứ Ba.
7. Thời gian bắt đầu, thời gian kết thúc xử lý dữ liệu cá nhân
7.1. Dữ Liệu Cá Nhân được Xử Lý kể từ thời điểm Chúng Tôi nhận được Dữ Liệu Cá Nhân một cách hợp pháp và Chúng Tôi đã có cơ sở pháp lý phù hợp để Xử Lý theo quy định Pháp Luật.
7.2. Dữ Liệu Cá Nhân sẽ được Xử Lý cho đến khi các mục đích Xử Lý đã được hoàn thành.
7.3. Chúng Tôi có thể phải lưu trữ Dữ Liệu Cá Nhân ngay cả khi quan hệ giữa các bên đã chấm dứt để thực hiện các nghĩa vụ theo quy định Pháp Luật và/hoặc yêu cầu của cơ quan nhà nước có thẩm quyền.
8. Quyền, nghĩa vụ của chủ thể dữ liệu
8.1. Quyền của Chủ Thể Dữ Liệu
8.1.1. Chủ Thể Dữ Liệu có các quyền sau:
8.1.1.1. Quyền được biết về hoạt động Xử Lý Dữ Liệu Cá Nhân của mình, trừ trường hợp Pháp Luật có quy định khác;
8.1.1.2. Quyền đồng ý hoặc không đồng ý cho phép Xử Lý Dữ Liệu Cá Nhân của mình, trừ trường hợp Pháp Luật quy định khác;
8.1.1.3. Quyền truy cập để xem, chỉnh sửa hoặc yêu cầu chỉnh sửa Dữ Liệu Cá Nhân của mình, trừ trường hợp pháp luật có quy định khác;
8.1.1.4. Quyền rút lại sự đồng ý, trừ trường hợp Pháp Luật có quy định khác;
8.1.1.5. Quyền xóa Dữ Liệu Cá Nhân hoặc yêu cầu xoá Dữ Liệu Cá Nhân của mình, trừ trường hợp Pháp Luật có quy định khác;
8.1.1.7. Quyền yêu cầu cung cấp cho bản thân Dữ Liệu Cá Nhân của mình, trừ trường hợp Pháp Luật có quy định khác;
8.1.1.8. Quyền phản đối Xử Lý Dữ Liệu Cá Nhân của mình nhằm ngăn chặn hoặc hạn chế tiết lộ Dữ Liệu Cá Nhân hoặc sử dụng cho mục đích quảng cáo, tiếp thị, trừ trường hợp Pháp Luật có quy định khác;
8.1.1.9. Quyền khiếu nại, tố cáo hoặc khởi kiện theo quy định Pháp Luật;
8.1.1.10. Quyền yêu cầu bồi thường thiệt hại theo quy định Pháp Luật khi xảy ra vi phạm quy định về bảo vệ Dữ Liệu Cá Nhân của mình, trừ trường hợp các bên có thỏa thuận khác hoặc Pháp Luật có quy định khác;
8.1.1.11. Quyền tự bảo vệ hoặc yêu cầu cơ quan, tổ chức có thẩm quyền thực hiện các phương thức bảo vệ quyền dân sự theo quy định Pháp Luật.
8.1.2. Chủ Thể Dữ Liệu có thể thực hiện các quyền này bằng việc liên hệ trực tiếp với Chúng Tôi.
8.1.3. Chúng Tôi sẽ xử lý các yêu cầu thực hiện quyền của Chủ Thể Dữ Liệu phù hợp với quy định Pháp Luật và cân nhắc quyền lợi chính đáng của Chủ Thể Dữ Liệu. Tuy nhiên, trong trường hợp Chủ Thể Dữ Liệu rút lại sự đồng ý của mình, yêu cầu xóa Dữ Liệu Cá Nhân và/hoặc thực hiện các quyền có liên quan khác đối với bất kỳ hoặc tất cả các Dữ Liệu Cá Nhân làm ảnh hưởng đến khả năng thực hiện hoặc duy trì việc tương tác và/hoặc thực hiện thoả thuận giữa Chúng Tôi và Chủ Thể Dữ Liệu, tuỳ thuộc vào tính chất yêu cầu của Chủ Thể Dữ Liệu, Chúng Tôi có thể xem xét và quyết định về việc không tiếp tục tương tác với Chủ Thể Dữ Liệu hoặc không cho phép Chủ Thể Dữ Liệu tương tác với Chúng Tôi hoặc chấm dứt thoả thuận giữa Chúng Tôi với Chủ Thể Dữ Liệu. Các hành vi được thực hiện bởi Chủ Thể Dữ Liệu theo quy định này sẽ được xem là sự đơn phương chấm dứt từ phía Chủ Thể Dữ Liệu cho bất kỳ mối quan hệ nào giữa Chủ Thể Dữ Liệu với Chúng Tôi và hoàn toàn có thể dẫn đến sự vi phạm nghĩa vụ hoặc các cam kết theo thoả thuận giữa Chủ Thể Dữ Liệu với Chúng Tôi và quy định Pháp Luật, đồng thời Chúng Tôi bảo lưu các quyền và biện pháp khắc phục hợp pháp của Chúng Tôi trong những trường hợp đó. Theo đó, Chúng Tôi sẽ không chịu trách nhiệm đối với Chủ Thể Dữ Liệu cho mọi thiệt hại (bao gồm nhưng không giới hạn ở thiệt hại trực tiếp, gián tiếp, ngẫu nhiên, đặc biệt, mang tính chất trừng phạt hoặc tương tự, hậu quả hoặc các thiệt hại khác) bất kể hình thức của hành động pháp lý hoặc lý thuyết pháp lý được áp dụng (bao gồm nhưng không giới hạn ở tranh chấp ngoài hợp đồng, trong hợp đồng, bảo hành, sơ suất), ngay cả khi Chúng Tôi đã được khuyến cáo, biết hoặc nên biết về khả năng xảy ra thiệt hại. Đồng thời, các quyền và lợi ích hợp pháp của Chúng Tôi sẽ được bảo lưu một cách đầy đủ. Bằng nỗ lực hợp lý, Chúng Tôi sẽ thực hiện yêu cầu hợp pháp và hợp lệ từ Chủ Thể Dữ Liệu trong thời gian phù hợp với quy định Pháp Luật. Tuy nhiên, vì mục đích bảo vệ, bảo mật, Chúng Tôi có thể yêu cầu Chủ Thể Dữ Liệu xác minh danh tính trước khi xử lý yêu cầu của Chủ Thể Dữ Liệu.
8.1.4. Chúng Tôi có quyền từ chối thực hiện các yêu cầu của Chủ Thể Dữ Liệu trong các trường hợp sau:
8.1.4.1. Chủ Thể Dữ Liệu không thực hiện đúng trình tự, thủ tục do Chúng Tôi hướng dẫn trong đó nội dung yêu cầu thiếu thông tin hoặc không hợp lệ;
8.1.4.2. Chủ Thể Dữ Liệu không cung cấp hoặc cung cấp không đầy đủ các giấy tờ, tài liệu để xác minh danh tính;
8.1.4.3. Chúng Tôi đánh giá có dấu hiệu gian lận, vi phạm về bảo vệ, bảo mật Dữ Liệu Cá Nhân; hoặc
8.1.4.4. Pháp Luật không cho phép thực hiện yêu cầu của Chủ Thể Dữ Liệu Cá Nhân.
8.2. Nghĩa vụ của Chủ Thể Dữ Liệu
8.2.1. Tự bảo vệ Dữ Liệu Cá Nhân; yêu cầu các tổ chức, cá nhân khác có liên quan bảo vệ Dữ Liệu Cá Nhân của mình.
8.2.2. Thông báo kịp thời cho Chúng Tôi khi phát hiện thấy có sai sót, nhầm lẫn, rò rỉ về Dữ Liệu Cá Nhân hoặc nghi ngờ Dữ Liệu Cá Nhân đang bị xâm phạm.
8.2.3. Tôn trọng, bảo vệ Dữ Liệu Cá Nhân của người khác.
8.2.4. Cung cấp đầy đủ, chính xác Dữ Liệu Cá Nhân khi đồng ý cho phép Xử Lý Dữ Liệu Cá Nhân. Nếu có bất kỳ thông tin sai lệch nào, Chủ Thể Dữ Liệu sẽ tự chịu bằng chi phí của mình trong trường hợp thông tin đó làm ảnh hưởng hoặc hạn chế quyền lợi của Chủ Thể Dữ Liệu.
8.2.5. Thực hiện quy định Pháp Luật về bảo vệ Dữ Liệu Cá Nhân và tham gia phòng, chống các hành vi vi phạm quy định về bảo vệ Dữ Liệu Cá Nhân.

 VietData.AI – Doanh nghiệp Việt đầu tiên tại Việt Nam đồng thời đạt danh hiệu Google Partner cho cả Google Cloud Platform & Google Marketing Platform, khẳng định năng lực tích hợp công nghệ và marketing vượt trội.
VietData.AI – Doanh nghiệp Việt đầu tiên tại Việt Nam đồng thời đạt danh hiệu Google Partner cho cả Google Cloud Platform & Google Marketing Platform, khẳng định năng lực tích hợp công nghệ và marketing vượt trội.